
The Foundation of Machine Learning: What, Why, and How it Began
Machine Learning (ML) represents a paradigm shift in how computers solve problems. At its core, ML is an AI subfield empowering systems to learn from data, identify patterns, and make decisions or predictions with minimal explicit programming. Unlike traditional programming, which relies on human-written, rule-based instructions for every conceivable scenario, ML models train on vast datasets. Instead of being explicitly told how to solve a problem, they infer rules and relationships from the data itself. For example, a traditional spam filter might use predefined keywords; an ML-based filter learns by analyzing thousands of labeled emails, independently discovering differentiating patterns and adapting over time.
While often used interchangeably, Machine Learning is distinct from, yet integral to, the broader concept of Artificial Intelligence (AI). AI encompasses the overarching goal of creating machines that simulate human intelligence—performing tasks like reasoning, problem-solving, perception, and language understanding. ML is one of the most powerful and widely adopted approaches within AI. Think of AI as the universe of intelligent systems, and ML as a powerful methodology focused on enabling learning from data. Other AI techniques exist, such as symbolic AI or expert systems, but modern AI's remarkable successes are predominantly fueled by Machine Learning advancements.
The seeds of Machine Learning were sown decades ago, with visionaries like Alan Turing pondering "learning machines" in the 1950s. The term "Machine Learning" itself was coined in 1959 by Arthur Samuel, an IBM pioneer, who developed a checkers program that improved its performance by learning from its own games. Samuel famously stated:
"Programming computers to learn from experience should not be confused with simply programming computers to play well. Learning implies the ability to change internal representations based on external inputs to improve future performance."
Frank Rosenblatt's Perceptron (1957) also introduced a foundational concept for neural networks. Despite these early breakthroughs, limited computational power and data led to "AI winters," where research often favored symbolic AI and rule-based systems over statistical learning.
The late 20th century marked a gradual resurgence of statistical and connectionist approaches. Key algorithmic advancements began overcoming earlier model limitations. The refinement of the backpropagation algorithm in the mid-1980s by researchers like Rumelhart, Hinton, and Williams reignited interest in neural networks, enabling multi-layered networks to learn complex patterns. The 1990s brought powerful algorithms like Support Vector Machines (SVMs) by Vapnik and Cortes, offering robust solutions for classification and regression. Other pivotal developments included decision trees and ensemble methods like Random Forests. These innovations, coupled with growing availability of digital data, set the stage for ML's eventual breakout.

The true explosion of Machine Learning into mainstream prominence in the 21st century stems from a powerful confluence of factors:
- Big Data: The digital age created an unprecedented era of data generation—every click, transaction, and sensor reading contributes to massive datasets, precisely what ML algorithms need to learn effectively.
- Computational Power: Advances in hardware, particularly Graphics Processing Units (GPUs), provided the immense parallel processing capabilities required to train complex ML models, especially deep neural networks. Cloud computing further democratized this access.
- Advanced Algorithms: Significant theoretical and practical breakthroughs, especially in Deep Learning (multi-layered neural networks), enabled models to tackle previously intractable problems. Architectures like Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformer networks unlocked capabilities once purely science fiction, aided by open-source frameworks like TensorFlow and PyTorch.
This perfect storm propelled Machine Learning from academic curiosity to a transformative technology reshaping industries worldwide. From powering personalized recommendations and optimizing supply chains, to enabling early disease detection and facilitating self-driving vehicles, ML unlocks unprecedented potential. It allows us to automate complex decision-making, uncover hidden insights in vast datasets, and create intelligent systems that adapt and evolve. Machine Learning is not merely an incremental improvement; it represents a fundamental shift in how we augment human intelligence and interact with the digital world, promising a future rich with intelligent applications.
The Core Paradigms: Supervised, Unsupervised, and Reinforcement Learning
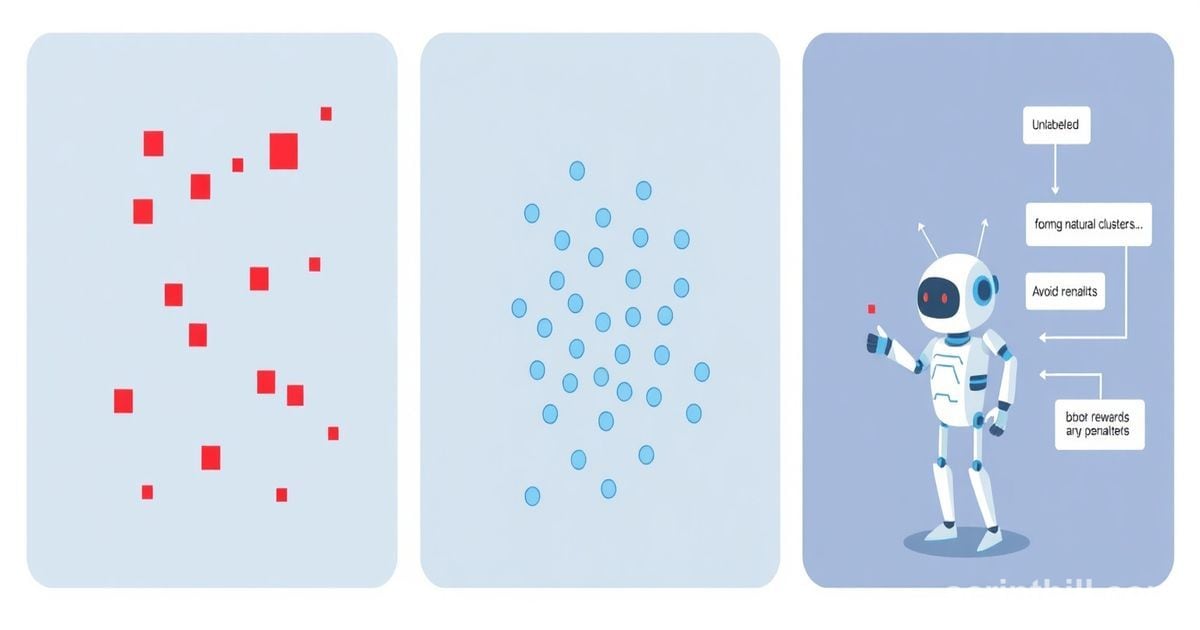
Machine Learning, at its heart, is about enabling systems to learn from data without explicit programming. This broad field can be categorized into three fundamental paradigms, each suited for different problem types and data structures: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Understanding these core approaches is crucial to grasping the landscape of modern AI.
Supervised Learning is arguably the most common and intuitive type of machine learning. It's akin to a student learning under the guidance of a teacher. The model is trained on a dataset that contains "labeled" examples—meaning each input data point is paired with its correct output or desired "label." The goal is for the model to learn a mapping function from inputs to outputs, so it can accurately predict the output for new, unseen inputs.
- Underlying Principles: Learning a function that maps input variables to an output variable based on example input-output pairs. The process involves minimizing the error between the model's predictions and the true labels.
- Data Requirement: Labeled datasets, where each input
Xhas a corresponding known outputy. - Typical Tasks:
- Classification: Predicting a categorical label (e.g., "spam" or "not spam," "cat" or "dog," "fraudulent" or "legitimate").
- Regression: Predicting a continuous numerical value (e.g., house prices, stock values, temperature).
- Real-world Use Cases:
- Spam Detection: Training a model on emails labeled as spam or not spam to identify future unsolicited messages.
- Medical Diagnosis: Using patient symptoms and test results to classify potential diseases.
- Image Recognition: Identifying objects or faces in images by learning from labeled image datasets.
Unsupervised Learning: Discovering Hidden Structures
In contrast to supervised learning, Unsupervised Learning deals with unlabeled data. Here, there's no "teacher" providing correct answers. Instead, the algorithm's task is to find inherent patterns, structures, or relationships within the data on its own. It's like finding different species of animals in an ecosystem without being told beforehand what those species are.
- Underlying Principles: Exploring data to find patterns, groupings, or dimensions that were not explicitly defined. It aims to infer the natural structure present within the data.
- Data Requirement: Unlabeled datasets, consisting only of input features
X. - Typical Tasks:
- Clustering: Grouping similar data points together based on their features (e.g., customer segmentation).
- Dimensionality Reduction: Reducing the number of features in a dataset while retaining most of the important information (e.g., for visualization or simplifying models).
- Anomaly Detection: Identifying unusual patterns that deviate significantly from the norm.
- Real-world Use Cases:
- Market Segmentation: Grouping customers into distinct segments based on purchasing behavior to tailor marketing strategies.
- Genomics: Discovering natural groupings of genes or cell types in biological data.
- Recommendation Systems: Identifying similar items that users might like based on their past preferences or browsing history.
Reinforcement Learning: Learning by Doing
Reinforcement Learning (RL) operates on a different paradigm, focusing on how an "agent" can learn to make sequential decisions in an "environment" to maximize a cumulative reward. There's no fixed dataset; instead, the agent learns through trial and error. It performs an action, observes the outcome (a new state and a reward or penalty), and uses this feedback to refine its strategy over time.
- Underlying Principles: An agent learns an optimal policy (a strategy) to choose actions in various states of an environment to maximize the cumulative reward. It's a continuous loop of "observe, act, get reward, learn."
- Data Requirement: No explicit dataset; learning occurs through interactions (observations, actions, rewards) with an environment.
- Typical Tasks: Sequential decision-making, control tasks, game playing, optimizing behaviors.
- Real-world Use Cases:
- Game AI: Training agents to play complex games like Chess or Go, often surpassing human performance.
- Robotics: Teaching robots to perform tasks such as grasping objects or navigating complex terrains without explicit programming for every move.
- Autonomous Vehicles: Developing systems that learn optimal driving strategies in dynamic and unpredictable environments.
To further illustrate the distinct nature of these paradigms, consider the following summary:
| Paradigm | Data Type | Objective | Example Task |
|---|---|---|---|
| Supervised Learning | Labeled (Input + Known Output) | Predict output for new inputs | Spam detection, Price prediction |
| Unsupervised Learning | Unlabeled (Input only) | Discover hidden patterns/structures | Customer segmentation, Data compression |
| Reinforcement Learning | Interaction (Observations, Actions, Rewards) | Maximize cumulative reward through actions | Game playing, Robot navigation |
This breakdown provides a foundational understanding of how different types of machine learning tackle distinct challenges, leveraging various forms of data and learning mechanisms.
Key Algorithms and Models: The Engine Room of ML
The true magic of Machine Learning unfolds within its algorithms and models – the precise instructions and structures that enable computers to learn from data. These aren't just arbitrary programs; they are sophisticated statistical and computational recipes, each suited to different tasks and data types. Understanding these "engine rooms" reveals how ML systems tackle complex problems.
In supervised learning, algorithms are trained on datasets where both the input features and the correct output labels are provided.
-
Decision Trees and Random Forests: Imagine a flowchart where each internal node represents a test on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label. A Decision Tree learns to split data based on features to arrive at a prediction. For instance, it might ask "Is the customer's age > 30?" and then "Is their income > $50k?" to decide if they'll buy a product.
- Strengths:
- Intuitive and easy to interpret (especially single trees).
- Can handle both numerical and categorical data.
- Random Forests, an ensemble of many Decision Trees, are highly robust and accurate.
- Weaknesses:
- Single Decision Trees can be prone to overfitting, memorizing the training data too closely.
- Random Forests are less interpretable due to their complexity.
- Strengths:
-
Support Vector Machines (SVMs): SVMs are powerful for classification tasks. Their core idea is to find the "best" hyperplane—a decision boundary—that separates data points of different classes in a high-dimensional space. The "best" hyperplane is the one with the largest margin between the two classes, meaning it sits as far as possible from the nearest data points of both classes.
- Strengths:
- Highly effective in high-dimensional spaces.
- Memory efficient as they use a subset of training points (support vectors).
- Versatile, thanks to different "kernel functions" that can handle non-linear relationships.
- Weaknesses:
- Can be computationally intensive for very large datasets.
- Sensitive to parameter tuning.
- Strengths:
Unsupervised Learning: Finding Patterns in Unlabeled Data
Unsupervised algorithms work with data that lacks explicit labels, aiming to discover hidden structures or representations.
-
K-Means Clustering: This algorithm groups data points into a predefined number of clusters,
K. It iteratively assigns each data point to the cluster whose center (centroid) is closest, then recalculates the centroids based on the new cluster assignments. This process repeats until the clusters stabilize.- Strengths:
- Simple to understand and implement.
- Computationally efficient and scales well to large datasets.
- Weaknesses:
- Requires the number of clusters (
K) to be specified beforehand. - Sensitive to the initial placement of centroids and outliers.
- Requires the number of clusters (
- Strengths:
-
Principal Component Analysis (PCA): PCA is a dimensionality reduction technique used to simplify complex datasets. It transforms the data into a new set of orthogonal (uncorrelated) features called principal components, ordered by the amount of variance they explain. The goal is to retain as much variation as possible with fewer dimensions, making the data easier to process and visualize.
- Strengths:
- Reduces the number of features, mitigating the "curse of dimensionality."
- Can remove noise and improve model performance.
- Weaknesses:
- Can lead to loss of interpretability of the new features.
- Assumes linear relationships between features.
- Strengths:
Reinforcement Learning: Learning Through Interaction
Reinforcement learning algorithms learn by interacting with an environment, performing actions, and receiving rewards or penalties.
-
Q-learning: A popular model-free reinforcement learning algorithm, Q-learning learns an optimal "policy" that tells an agent what action to take in a given state to maximize cumulative future rewards. It does this by building a "Q-table" (or estimating Q-values), which stores the expected utility of taking a particular action in a particular state. The agent updates these Q-values based on the rewards it receives.
# Simplified Q-learning update ruleQ[state, action] = Q[state, action] + alpha * (reward + gamma * max(Q[next_state, :]) - Q[state, action])# Where:# alpha is the learning rate# gamma is the discount factor for future rewards# max(Q[next_state, :]) is the maximum Q-value for the next state- Strengths:
- Model-free, meaning it doesn't require an understanding of the environment's dynamics.
- Can learn complex policies in challenging environments.
- Weaknesses:
- The Q-table can become prohibitively large for environments with many states and actions.
- Can be slow to converge for large state-action spaces.
- Strengths:
Neural Networks and Deep Learning: A Specialized Powerhouse
While many of the above algorithms excel, a distinct class of models known as Neural Networks (NNs) has revolutionized ML, leading to the rise of Deep Learning. Inspired by the human brain, NNs consist of interconnected layers of "neurons" that process information in a hierarchical manner. Each neuron takes inputs, applies a transformation, and passes the output to subsequent neurons.
Deep Learning refers to Neural Networks with many layers ("deep" architectures). These networks are exceptionally good at learning complex, abstract representations directly from raw data, which is why they dominate fields like image recognition, natural language processing, and speech synthesis. Their ability to automatically discover intricate patterns makes them a uniquely powerful and versatile tool in the ML arsenal.
ML in Action: Real-World Applications Across Industries
Machine Learning (ML) is no longer a niche academic pursuit; it is the silent engine powering much of the modern world, embedding itself deeply into the fabric of our daily lives. From personal recommendations to life-saving medical diagnoses, ML's pervasive influence solves complex problems across virtually every industry, enhancing efficiency, accuracy, and innovation.
In healthcare, ML is revolutionizing diagnostics, drug discovery, and personalized treatment.
- Enhanced Diagnostics: ML algorithms are adept at analyzing medical images (X-rays, MRIs, CT scans) to detect subtle anomalies that might escape the human eye. For instance, ML models can identify early signs of cancer, retinopathy in diabetic patients, or even predict the risk of heart disease from medical scans with remarkable accuracy.
- Accelerated Drug Discovery: Pharmaceutical companies leverage ML to sift through vast chemical databases, predicting potential drug candidates and their interactions. This significantly speeds up the research and development process, reducing both time and cost.
- Personalized Medicine: By analyzing a patient's genetic data, medical history, and lifestyle factors, ML can recommend highly personalized treatment plans, optimizing efficacy and minimizing adverse effects.
Finance and Banking
The financial sector has embraced ML for its ability to process massive datasets and identify patterns, leading to more secure and efficient operations.
- Fraud Detection: ML models continuously monitor transactions, flagging suspicious activities in real-time. By learning from historical fraud patterns, these systems can identify new forms of fraudulent behavior, protecting both banks and customers.
- Algorithmic Trading: High-frequency trading firms use ML algorithms to analyze market data, predict price movements, and execute trades at optimal times, often within milliseconds.
- Credit Scoring and Risk Management: ML provides more nuanced credit assessments by considering a wider range of data points than traditional methods, leading to fairer lending decisions and better risk prediction for loan portfolios.
E-commerce and Retail
ML is at the heart of the personalized digital experiences we've come to expect in online shopping.
- Recommendation Systems: Platforms like Amazon and Netflix utilize ML to analyze user behavior, purchase history, and preferences, recommending products, movies, or music tailored to individual tastes. This drives engagement and sales.
- Personalized Marketing: ML helps retailers target customers with highly relevant ads and promotions, optimizing marketing spend and improving conversion rates by understanding individual customer journeys and likely purchasing behaviors.
- Dynamic Pricing and Inventory Management: Algorithms adjust product prices in real-time based on demand, competitor pricing, and inventory levels, while also predicting future demand to optimize stock.
Natural Language Processing (NLP)
NLP, a core ML discipline, has transformed how machines understand and interact with human language.
- Chatbots and Virtual Assistants: AI-powered chatbots handle customer service queries, while virtual assistants like Siri and Alexa understand spoken commands, performing tasks from setting reminders to providing information.
- Machine Translation: Tools like Google Translate use sophisticated ML models to accurately translate text and speech between languages, breaking down communication barriers globally.
- Sentiment Analysis: Businesses use NLP to gauge public opinion about their brands, products, or services by analyzing text data from social media, reviews, and news articles.
Computer Vision
Computer Vision, another significant branch of ML, enables machines to "see" and interpret images and videos.
- Facial Recognition: Used for security, authentication (e.g., unlocking smartphones), and identifying individuals in public spaces.
- Autonomous Vehicles: Self-driving cars rely heavily on computer vision to interpret their surroundings, detect pedestrians, other vehicles, traffic signs, and lane markings, enabling safe navigation.
- Quality Control in Manufacturing: ML-powered vision systems inspect products on assembly lines for defects, ensuring high-quality output faster and more consistently than human inspection.
The applications listed above merely scratch the surface of ML's reach. Its adaptability means that new uses are constantly emerging, fundamentally reshaping industries from agriculture and energy to education and scientific research.
| Industry | Key ML Applications | Example |
|---|---|---|
| Healthcare | Predictive Diagnostics, Drug Discovery | Early cancer detection |
| Finance | Fraud Detection, Algorithmic Trading | Real-time transaction monitoring |
| E-commerce | Recommendation Systems, Personalized Ads | "Customers also bought..." suggestions |
| NLP | Chatbots, Machine Translation | Customer service automation |
| Computer Vision | Autonomous Driving, Facial Recognition | Object detection in self-driving cars |
Challenges, Limitations, and Ethical AI: Navigating the Complexities
While machine learning offers immense promise, its journey from concept to real-world application is fraught with practical challenges and critical ethical considerations that demand careful navigation. Ignoring these complexities can lead to systems that are not only ineffective but also harmful.
Developing and deploying robust ML systems involves wrestling with several key practical issues:
- Data Quality and Availability: The axiom "garbage in, garbage out" holds true for ML. Models learn patterns from data, so if the training data is incomplete, inaccurate, inconsistent, or simply insufficient, the model's performance will suffer dramatically. Acquiring, cleaning, labeling, and preprocessing vast amounts of high-quality data is often the most time-consuming and expensive part of an ML project.
- Bias in Datasets: Perhaps one of the most insidious practical challenges is inherent bias within datasets. If the data used to train a model reflects existing societal biases (e.g., historical discrimination in hiring, lending, or law enforcement), the ML system will learn and perpetuate these biases, potentially leading to discriminatory outcomes against certain demographic groups.
- Model Interpretability (The "Black Box" Problem): Many powerful ML models, particularly deep neural networks, are often referred to as "black boxes" because their decision-making processes are opaque and difficult for humans to understand. This lack of interpretability can hinder debugging efforts, erode trust, and create significant challenges for regulatory compliance or explaining decisions in critical domains like healthcare or criminal justice.
- Computational Resource Demands: Training sophisticated ML models, especially large deep learning architectures, requires significant computational power. This translates into demands for specialized hardware (like GPUs or TPUs), considerable energy consumption, and often access to cloud computing resources, making it a costly endeavor that can be a barrier for smaller organizations or researchers.
Critical Ethical Considerations
Beyond the practicalities, the deployment of ML systems raises profound ethical questions that society must collectively address.
- Fairness and Discrimination: How do we ensure ML models treat all individuals and groups fairly? Bias in data or algorithms can lead to discriminatory outcomes in areas such as credit scoring, job applications, or even medical diagnoses, exacerbating existing societal inequalities.
- Privacy Concerns: ML often relies on vast amounts of personal data. This raises concerns about how data is collected, stored, and used, the potential for re-identification of anonymized data, and the risk of unauthorized access or misuse of sensitive information.
- Security Vulnerabilities: ML models are not immune to malicious attacks. Adversarial attacks can subtly alter inputs to trick a model into misclassifying data, while data poisoning can compromise the integrity of training data, leading to a compromised model.
- Accountability: When an ML system makes a flawed or harmful decision, who is accountable? Is it the data scientist who built the model, the company that deployed it, the organization that provided the data, or the user who interacted with it? Establishing clear lines of responsibility is crucial, especially in autonomous systems.
- Potential for Societal Harm: Beyond direct individual harm, unchecked or poorly implemented AI can have broader societal implications, including job displacement, the spread of misinformation, increased surveillance, and the potential for autonomous weapons systems.
"The greatest danger in the age of AI is not that machines will develop consciousness, but that humans will allow them to make decisions without understanding the implications." – Unknown
The Imperative for Responsible AI Development and Governance
Addressing these challenges and ethical considerations is not merely an academic exercise; it's an imperative for the responsible advancement of machine learning. This requires a multi-faceted approach:
- Ethical AI by Design: Integrating ethical considerations from the very initial stages of development, including data collection, model design, and deployment strategy.
- Transparency and Explainability: Investing in Explainable AI (XAI) research to develop methods that make complex models more interpretable and their decisions understandable to humans.
- Bias Detection and Mitigation: Implementing rigorous processes for identifying and mitigating bias in datasets and algorithms throughout the ML lifecycle.
- Robust Security Measures: Developing and deploying ML systems with strong cybersecurity protocols to protect against adversarial attacks and data breaches.
- Regulatory Frameworks and Governance: Establishing clear legal and ethical guidelines, industry standards, and regulatory bodies to oversee the development and deployment of AI, ensuring accountability and preventing misuse.
- Public Education and Engagement: Fostering a more informed public discourse about AI's capabilities, limitations, and ethical implications.
Embracing these principles is vital to harnessing the transformative power of ML while safeguarding against its potential pitfalls, ensuring that AI serves humanity's best interests.
The Future of Machine Learning: Emerging Trends and Transformative Impact
Content unavailable for this section.

